How to Create Your Own RAG with Free LLM Models and a Knowledge Base
This article explores the implementation of a straightforward yet effective question-answering system that combines modern transformer-based models. The system uses T5 (Text-to-Text Transfer Transformer) for answer generation and Sentence Transformers for semantic similarity matching.

In my previous article, I explained how to create a simple translation API with a web interface using a free foundational LLM model. This time, let’s dive into building a Retrieval-Augmented Generation (RAG) system using free transformer-based LLM models and a knowledge base.
RAG (Retrieval-Augmented Generation) is a technique that combines two key components:
Retrieval: First, it searches through a knowledge base (like documents, databases, etc.) to find relevant information for a given query. This usually involves:
Converting text into embeddings (numerical vectors that represent meaning)
Finding similar content using similarity measures (like cosine similarity)
Selecting the most relevant pieces of information
Generation: Then it uses a language model (like T5 in our code) to generate a response by:
Combining the retrieved information with the original question
Creating a natural language response based on this context
In our code:
- The
SentenceTransformerhandles the retrieval part by creating embeddings - The
T5model handles the generation part by creating answers
Benefits of RAG:
- More accurate responses since they’re grounded in specific knowledge
- Reduced hallucination compared to pure LLM responses
- Ability to access up-to-date or domain-specific information
- More controllable and transparent than pure generation
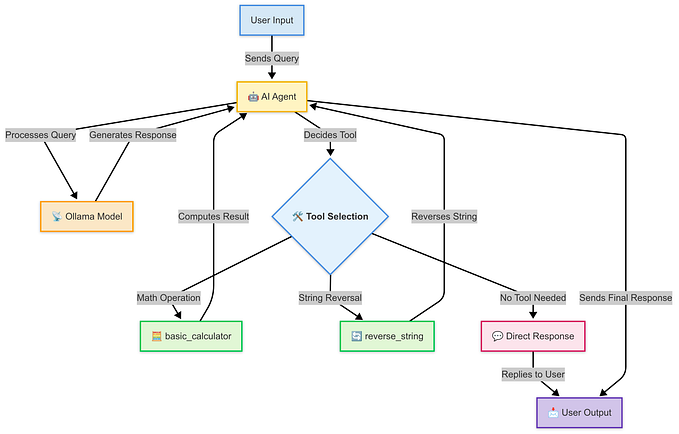
System Architecture Overview
The implementation consists of a SimpleQASystem class that orchestrates two main components:
- A semantic search system using Sentence Transformers
- An answer generation system using T5
You can download the latest version of source code here: https://github.com/alexander-uspenskiy/rag_project
System Diagram

RAG Project Setup Guide
This guide will help you set up your Retrieval-Augmented Generation (RAG) project on both macOS and Windows.
Prerequisites
For macOS:
- Install Homebrew (if not already installed):
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"- Install Python 3.8+ using Homebrew
brew install python@3.10For Windows:
- Download and install Python 3.8+ from python.org
- Make sure to check “Add Python to PATH” during installation
Project Setup
Step 1: Create Project Directory
macOS:
mkdir RAG_project
cd RAG_projectWindows:
mkdir RAG_project
cd RAG_projectStep 2: Set Up Virtual Environment
macOS:
python3 -m venv venv
source venv/bin/activateWindows:
python -m venv venv
venv\Scripts\activateCore Components
1. Initialization
def __init__(self):
self.model_name = 't5-small'
self.tokenizer = T5Tokenizer.from_pretrained(self.model_name)
self.model = T5ForConditionalGeneration.from_pretrained(self.model_name)
self.encoder = SentenceTransformer('paraphrase-MiniLM-L6-v2')The system initializes with two primary models:
- T5-small: A smaller version of the T5 model for generating answers
- paraphrase-MiniLM-L6-v2: A sentence transformer model for encoding text into meaningful vectors
2. Dataset Preparation
def prepare_dataset(self, data: List[Dict[str, str]]):
self.answers = [item['answer'] for item in data]
self.answer_embeddings = []
for answer in self.answers:
embedding = self.encoder.encode(answer, convert_to_tensor=True)
self.answer_embeddings.append(embedding)The dataset preparation phase:
- Extracts answers from the input data
- Creates embeddings for each answer using the sentence transformer
- Stores both answers and their embeddings for quick retrieval
How the System Works
1. Question Processing
When a user submits a question, the system follows these steps:
Embedding Generation: The question is converted into a vector representation using the same sentence transformer model used for the answers.
Semantic Search: The system finds the most relevant stored answer by:
- Computing cosine similarity between the question embedding and all answer embeddings
- Selecting the answer with the highest similarity score
Context Formation: The selected answer becomes the context for T5 to generate a final response.
2. Answer Generation
def get_answer(self, question: str) -> str:
# ... semantic search logic ...
input_text = f"Given the context, what is the answer to the question: {question} Context: {context}"
input_ids = self.tokenizer(input_text, max_length=512, truncation=True,
padding='max_length', return_tensors='pt').input_ids
outputs = self.model.generate(input_ids, max_length=50, num_beams=4,
early_stopping=True, no_repeat_ngram_size=2The answer generation process:
- Combines the question and context into a prompt for T5
- Tokenizes the input text with a maximum length of 512 tokens
- Generates an answer using beam search with these parameters:
- max_length=50: Limits answer length
- num_beams=4: Uses beam search with 4 beams
- early_stopping=True: Stops generation when all beams reach an end token
- no_repeat_ngram_size=2: Prevents repetition of bigrams
3. Answer Cleaning
def clean_answer(self, answer: str) -> str:
words = answer.split()
cleaned_words = []
for i, word in enumerate(words):
if i == 0 or word.lower() != words[i-1].lower():
cleaned_words.append(word)
cleaned = ' '.join(cleaned_words)
return cleaned[0].upper() + cleaned[1:] if cleaned else cleaned- Removes duplicate consecutive words (case-insensitive)
- Capitalizes the first letter of the answer
- Removes extra whitespace
Full Source Code
You can download the latest version of source code here: https://github.com/alexander-uspenskiy/rag_project
import os
# Set tokenizers parallelism before importing libraries
os.environ["TOKENIZERS_PARALLELISM"] = "false"
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
from typing import List, Dict
import numpy as np
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
class SimpleQASystem:
def __init__(self):
"""Initialize QA system using T5"""
try:
# Use T5 for answer generation
self.model_name = 't5-small'
self.tokenizer = T5Tokenizer.from_pretrained(self.model_name, legacy=False)
self.model = T5ForConditionalGeneration.from_pretrained(self.model_name)
# Move model to CPU explicitly to avoid memory issues
self.device = "cpu"
self.model = self.model.to(self.device)
# Initialize storage
self.answers = []
self.answer_embeddings = None
self.encoder = SentenceTransformer('paraphrase-MiniLM-L6-v2')
print("System initialized successfully")
except Exception as e:
print(f"Initialization error: {e}")
raise
def prepare_dataset(self, data: List[Dict[str, str]]):
"""Prepare the dataset by storing answers and their embeddings"""
try:
# Store answers
self.answers = [item['answer'] for item in data]
# Encode answers using SentenceTransformer
self.answer_embeddings = []
for answer in self.answers:
embedding = self.encoder.encode(answer, convert_to_tensor=True)
self.answer_embeddings.append(embedding)
print(f"Prepared {len(self.answers)} answers")
except Exception as e:
print(f"Dataset preparation error: {e}")
raise
def clean_answer(self, answer: str) -> str:
"""Clean up generated answer by removing duplicates and extra whitespace"""
words = answer.split()
cleaned_words = []
for i, word in enumerate(words):
if i == 0 or word.lower() != words[i-1].lower():
cleaned_words.append(word)
cleaned = ' '.join(cleaned_words)
return cleaned[0].upper() + cleaned[1:] if cleaned else cleaned
def get_answer(self, question: str) -> str:
"""Get answer using semantic search and T5 generation"""
try:
if not self.answers or self.answer_embeddings is None:
raise ValueError("Dataset not prepared. Call prepare_dataset first.")
# Encode question using SentenceTransformer
question_embedding = self.encoder.encode(
question,
convert_to_tensor=True,
show_progress_bar=False
)
# Move the question embedding to CPU (if not already)
question_embedding = question_embedding.cpu()
# Find most similar answer using cosine similarity
similarities = cosine_similarity(
question_embedding.numpy().reshape(1, -1), # Use .numpy() for numpy compatibility
np.array([embedding.cpu().numpy() for embedding in self.answer_embeddings]) # Move answer embeddings to CPU
)[0]
best_idx = np.argmax(similarities)
context = self.answers[best_idx]
# Generate the input text for the T5 model
input_text = f"Given the context, what is the answer to the question: {question} Context: {context}"
print(input_text)
# Tokenize input text
input_ids = self.tokenizer(
input_text,
max_length=512,
truncation=True,
padding='max_length',
return_tensors='pt'
).input_ids.to(self.device)
# Generate answer with limited max_length
outputs = self.model.generate(
input_ids,
max_length=50, # Increase length to handle more detailed answers
num_beams=4,
early_stopping=True,
no_repeat_ngram_size=2
)
# Decode the generated answer
answer = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
# Print the raw generated answer for debugging
print(f"Generated answer before cleaning: {answer}")
# Clean up the answer
cleaned_answer = self.clean_answer(answer)
return cleaned_answer
except Exception as e:
print(f"Error generating answer: {e}")
return f"Error: {str(e)}"
def main():
"""Main function with sample usage"""
try:
# Sample data
data = [
{"question": "What is the capital of France?", "answer": "The capital of France is Paris."},
{"question": "What is the largest planet?", "answer": "The largest planet is Jupiter."},
{"question": "Who wrote '1984'?", "answer": "George Orwell wrote '1984'."}
]
# Initialize system
print("Initializing QA system...")
qa_system = SimpleQASystem()
# Prepare dataset
print("Preparing dataset...")
qa_system.prepare_dataset(data)
# Start interactive Q&A session
while True:
# Prompt the user for a question
test_question = input("\nPlease enter your question (or 'exit' to quit): ")
if test_question.lower() == 'exit':
print("Exiting the program.")
break
# Get and print the answer
print(f"\nQuestion: {test_question}")
answer = qa_system.get_answer(test_question)
print(f"Answer: {answer}")
except Exception as e:
print(f"Error in main: {e}")
if __name__ == "__main__":
main()Performance ConsiderationsMemory Management:
- The system explicitly uses CPU to avoid memory issues
- Embeddings are converted to CPU tensors when needed
- Input length is limited to 512 tokens
Error Handling:
- Comprehensive try-except blocks throughout the code
- Meaningful error messages for debugging
- Validation checks for uninitialized components
Usage Example
# Initialize system
qa_system = SimpleQASystem()# Prepare sample data
data = [
{"question": "What is the capital of France?", "answer": "The capital of France is Paris."},
{"question": "What is the largest planet?", "answer": "The largest planet is Jupiter."}
]# Prepare dataset
qa_system.prepare_dataset(data)# Get answer
answer = qa_system.get_answer("What is the capital of France?")
Run in terminal

Limitations and Potential Improvements
Scalability:
- The current implementation keeps all embeddings in memory
- Could be improved with vector databases for large-scale applications
Answer Quality:
- Relies heavily on the quality of the provided answer dataset
- Limited by the context window of T5-small
- Could benefit from answer validation or confidence scoring
Performance:
- Using CPU only might be slower for large-scale applications
- Could be optimized with batch processing
- Could implement caching for frequently asked questions
Conclusion
This implementation provides a solid foundation for a question-answering system, combining the strengths of semantic search and transformer-based text generation. Feel free to play with model parameters (like max_length, num_beams, early_stopping, no_repeat_ngram_size, etc) to find a better way to get more coherent and stable answers. While there’s room for improvement, the current implementation offers a good balance between complexity and functionality, making it suitable for educational purposes and small to medium-scale applications.
Happy coding!